


Redis is a simple in-memory key value database mainly used for caching. Redis used to be a simple in-memory database. Now Redis is much more than that. Thanks to Redis modules, apart from the simple data structures such as strings, sets, maps, streams, etc. Redis can now support more complicated operations and data structures like full text search, json, graph and many more. In this article we will look into two components of Redis Stack. RediSearch and RedisJSON are two powerful plugins built top on Redis.

If you want to use RedisJSON/RediSearch and try along, check out docker installation or use Redis cloud free account. Redis cloud gives out $200 credit for free for new accounts.
RedisJSON
Json is the default language of web. Json is so powerful that we all started using json databases like MongoDB and DynamoDB everywhere in our applications. Now Redis supports json natively, Thanks to RedisJSON. Before RedisJSON the only way to store json inside Redis was by serialising and deserialising into Json and string back and forth. Or we can use Hash to store Json, but Hash only supports single level, to store multi level Json we have to include keys inside Hashes. All of this adds up as overhead to our application.
But with RedisJSON we have all the control to store and manipulate json natively. RedisJSON provides all the control but with best latency ever possible.
Once you have a Redis database ready we can start interacting with it. RedisInsight is the best GUI available to interact with Redis and Redis modules.
RedisInsight GUI - Adding database
As you can see above after installation use the “ADD REDIS DATABASE” option to add your database and connect to the database. Explaining everything inside RedisInsight is far from the scope of this article. But for now we can use the Workbench and Command Helper to check out the RedisJSON and RediSearch.
Let’s look at the Redis module command structure.
<MODULE>.<OPERATION> KEY VALUE/PATH .
This is the usual structure of a Redis module command. Let’s look at couple of RedisJSON command we are going to use for our very interesting project we are going to do. Let’s store a simple json data to Redis.
JSON.SET milkyway $ '{"age": "13B", "members": ["Mercury", "Venus", "Earth", "Mars", "Jupitor", "Saturn", "Uranus", "Neptune", "Pluto"]}'
Here milkyway is the key of the document and $ denotes that it is the root of the document. Run this command inside the workbench and you will get "OK" as response. Congratulation you have successfully stored a json document inside Redis.
Now let’s retrieve the Json document stored using the key.
JSON.GET milkyway $
The above command returns then entire document stored. What if you only want to access the array inside the document ? Use the following command.
JSON.MGET milkyway $..members
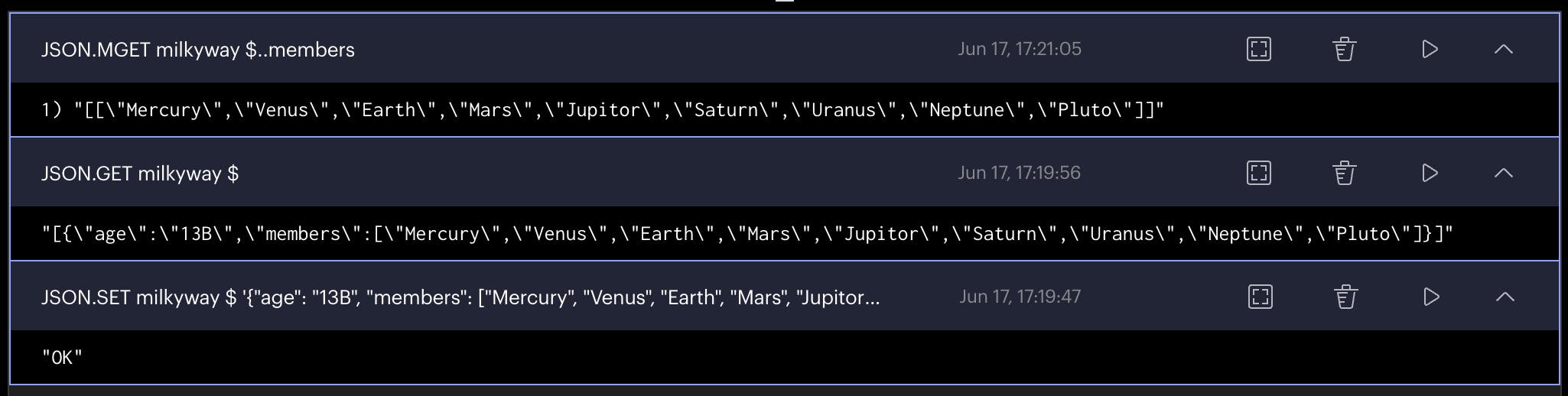
You can see all the outputs of the commands we tried in the above screenshot. Now let’s kick it up a notch by trying more complicated commands. First of all we have to remove Pluto from list of planets, Thanks to Neil deGrasse Tyson. We can pop our little dwarf planet out by JSON.ARRPOP command. This will remove the last element of the array.
JSON.ARRPOP milkyway $..members
Next up we can update the age our galaxy from 13 Billion to 13.6 Billion, Turns out 600 Million years is a very long time. We can use the same command used to create the document to update the document.
JSON.SET milkyway $.age '"13.6B"'
These are the basic commands inside the JSON Module. Check out the entire list of commands here.
RediSearch
full-text search refers to techniques for searching a single computer-stored document or a collection in a full-text database.
RediSearch is a full-text search and indexing module built on top of Redis. RediSearch provides a simple and fast way to index and query data using any field, and do search and aggregation on an indexed dataset. RediSearch gives super powers to your Redis cache or database.
We can store data inside hash and create indexes on top of those records. This makes RediSearch very powerful and dynamic. Previously we had to query the entire data and iterate through it to search or modify. Now we can do complex aggregations like grouping and ordering on the data through queries. Since it’s built on top of Redis it is really fast.
The real magic is when you combine both RedisJSON and RediSearch. Apart from native data structures Redis supports indexing of json data too. This is the super power I mentioned.
Let’s look into the basic commands of RediSearch inside the demo.
Demo
Apart from coding, I am a passionate reader and I love fantasy. So I combined both of my interest to come up with this demo idea. I want to store basic details of my favourite books inside Redis and build an api endpoint to retrieve information of the book. It’s nothing fancy but enough to dabble with most of the concept of RedisJSON and RediSearch.
First of all we need to insert json data(book data) into Redis for us to create indexes. I am using a simple javascript to upload all the book details to Redis
async function insertJSON() {
try {
if (process.argv.length < 3) {
console.error("json filepath to be provided.")
process.exit(1);
}
// read json file
let buf = fs.readFileSync(path.join(__dirname, process.argv[2]));
let JSONStr = buf.toString();
let books = JSON.parse(JSONStr);
const client = createClient();
await client.connect();
for (let i = 0; i < books.length; i++) {
const book = books[i];
const key = "book:" + book.name.toLowerCase().replaceAll(" ", "_");
let r = await client.json.set(key, '.', book);
console.log(key, " - ", r);
}
await client.quit();
} catch (e) {
console.error(e);
}
}
Here I am not focusing too much on the key structure since my requirement is less complex and it is not relevant, But good key structure is always important for better access. All code examples and book json file are available in this repo. Check out Github repo to follow along.
Now we have all the json documents stored inside Redis, which can be easily accessed, updated and manipulated natively.
Note that inserting json data is not necessary to create new indexes. Indexes can be created independent whether documents exist or not, pre existing json documents will get indexed once the index is created.
Create json indexes
Full-text search module commands follows the same format of json module commands. All commands starts with FT - Full text search.
FT.CREATE {index_name} ON JSON PREFIX {count} {prefix} SCHEMA {identifier} AS {attribute} {attribute_type}...
index_name- This is the custom name that can be given to the index created. Usuallyidx:<key>is used as a conventionsON JSON/HASH- Index can only be created on these both datatypes. (Default value is HASH)PREFIX {count} {prefix}- Prefix keyword mentions the structure of the keys to be indexed. Count is the number of prefixes to be indexed and we can provide multiple key prefixes. Default value is*, which is all the keys. Consider our document key structure asbook:the_book, to index all our document usePREFIX 1 book:.SCHEMA {identifier} AS {attribute} {type}...- This is the schema definition part of the command. identifier is the name of the field to be indexed. For Hashes it the name of the field. For json it is the path to the json value. attribute is the alternate name to be given to easily identify the field and index. Attribute type follows the attribute type - type of index to be created for this field (NUMERIC, TEXT and TAG)
Let’s look at a single entry of our document.
{
"name": "The Book", // text
"author": "Sam",
"year": "2020", // text
"rating": 5, // numeric sortable
"cover": "image.png",
"description": "..." // text
}
From the above document let’s create the index for our library dataset. name, year and description fields are indexed as text. rating is indexed as number and sortable, so we can do sorting on ratings.
Following command creates all the indexes we need with name idx:books.
FT.CREATE idx:books ON JSON PREFIX 1 book: SCHEMA $.name AS name TEXT $.author AS author TEXT $.rating AS rating NUMERIC SORTABLE $.description AS description TEXT
Queries
Now we can start querying using SEARCH Operation.
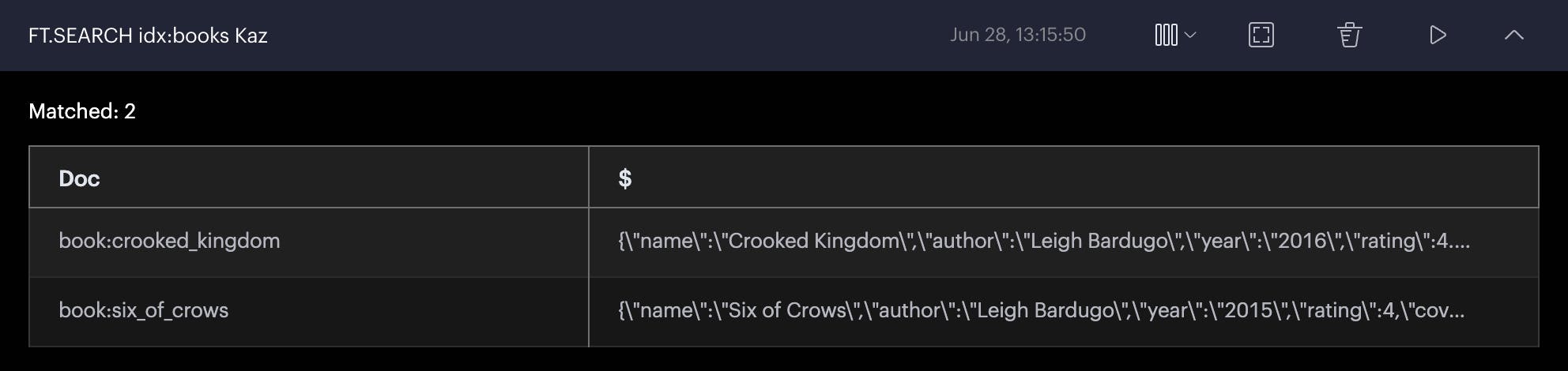
Simple Search on the book index. This returns all the json records with the word ‘Kaz’ indexed in any of the ‘TEXT’ attribute.
FT.SEARCH idx:books Kaz
Output
To search a word only in a single attribute use @{attribute-name}:{word}.
FT.SEARCH idx:books '@description:Kaz'
To select fields to be returned use RETURN {count} {fields...}
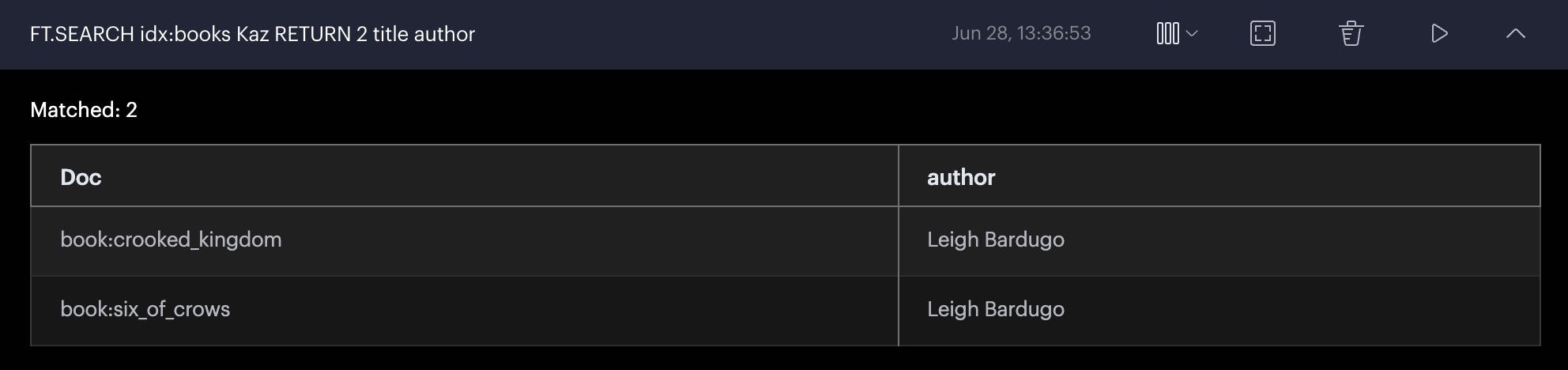
FT.SEARCH idx:books Kaz RETURN 2 name author
Output
Sorting
To sort the output according to the rating we can use SORTBY and ASC/ DESC to sort in ascending order or descending order.
FT.SEARCH idx:books * SORTBY rating DESC RETURN 2 name rating
Output
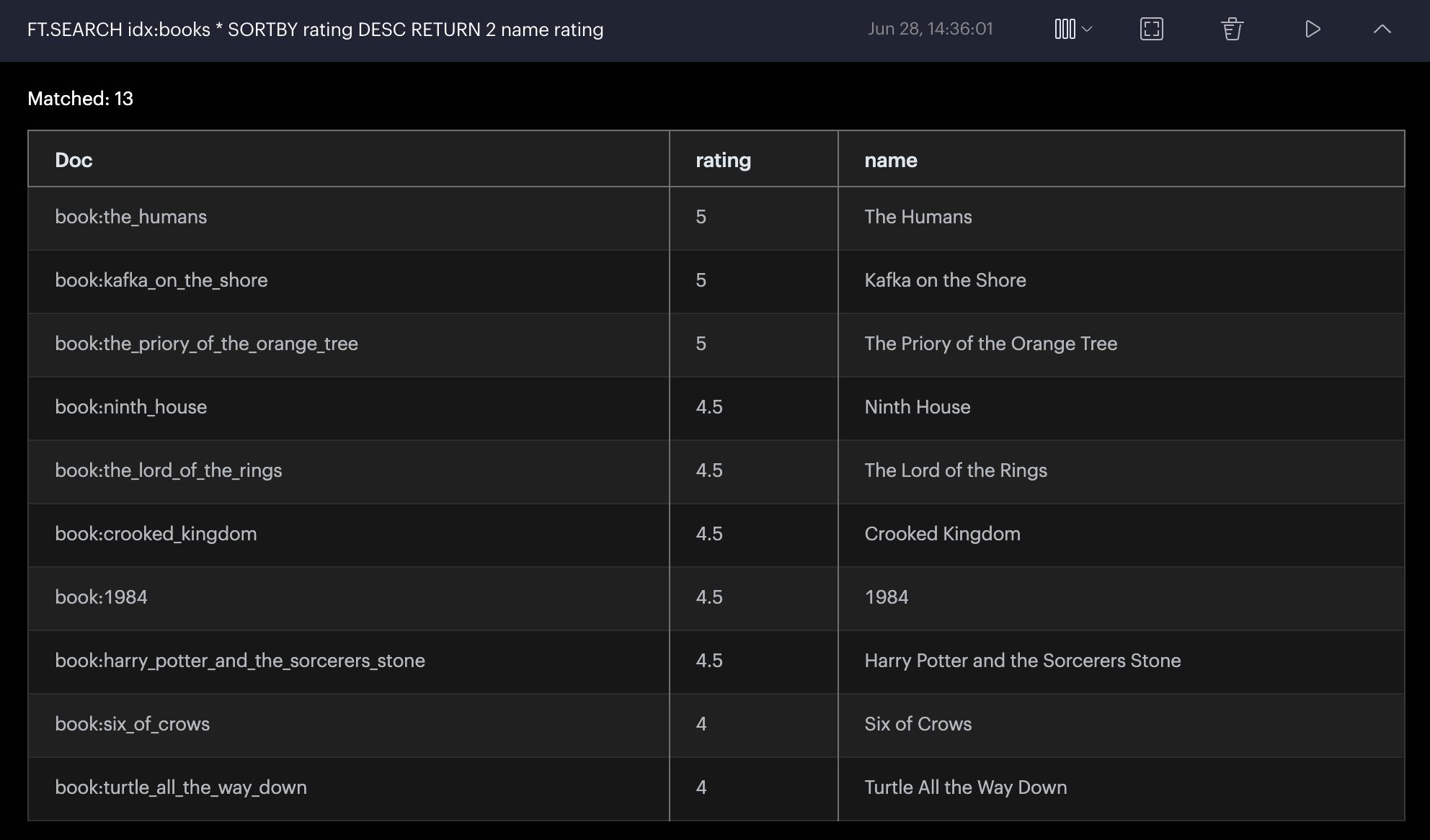
There is more cool stuff you can do with SEARCH. Check out more commands here.
Aggregation
AGGREGATE extends the capability of full text search module. Aggregations can be done on the data instead of simply fetching the data using SEARCH.
Explaining the entire aggregation would be so long and out of scope of this article. But to understand the flexibility let’s look at some of requirement for out library application and solve it.
I want to find the top 5 authors I read most. Following AGGREGATE query will fetch the top authors I read most.
FT.AGGREGATE idx:books * GROUPBY 1 @author REDUCE COUNT 0 AS no_of_books SORTBY 2 @no_of_books DESC LIMIT 0 5
Output
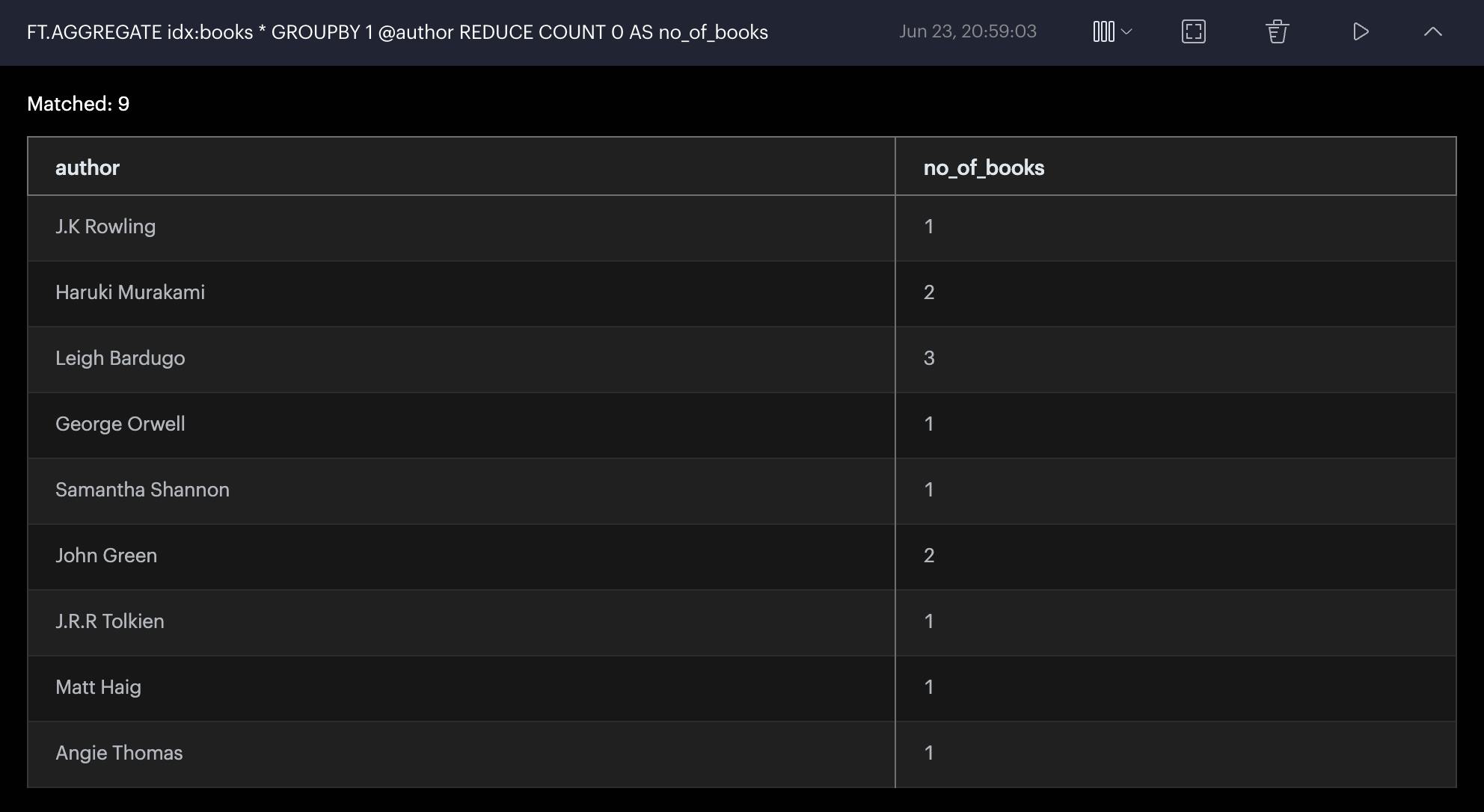
Looks like I am fan of Leigh Bardugo (Which is absolutely correct).
AGGREGATE- Aggregation queryGROUPBY- Group by operator to group all the docs with same authorREDUCE- As the name suggest REDUCE is used on top of Grouped docs to reduce the docs in to a singe doc.COUNT- Function to be executed on Grouped docs to reduce in to a single. count returns the number of records in a group. AS can be used to give a name for the value.
SORTBY- To sort the record on a sortable attribute. In this case it is the calculated value no_of_books. The *format of SORTBY is little different from theSEARCHquery, here we have to mention the nargs (number of arguments following SORTBY*)LIMIT- Limits the number of documents returned. We can paginate the result by providing the offset value after LIMIT and number of documents to be returned after offset.
Check out this repo for nodejs implementation of Redis full text search queries in this article.
Conclusion
Redis is a full fledged no-sql database with reliability and flexibility. Redis modules makes Redis more powerful and usable. Since it’s an in-memory database your queries can achieve crazy response times.
This post is in collaboration with Redis.
Try Redis Cloud for free